Online scraping enables you to gather open data from websites for purposes such as pricing comparison, market research, ad verification, etc.
Large amounts of the necessary public data are typically extracted, but when you run against blockades, the extraction might become challenging.
The restriction may be either rate-blocking or IP blocking (the request’s IP address is restricted because it originates from a prohibited area, prohibited type of IP, etc). (the IP address is blocked because it has made multiple requests).

Now if you are up for scraping some useful knowledge and information, then I’m sure you must have considered scraping Wikipedia, the knowledge encyclopedia that is home to tons of information.
Let’s understand a few things about web scraping Wikipedia.
Wikipedia Web Scraping
Web scraping is an automated method of gathering data from the internet. In-depth information about web scraping, a comparison to web crawling, and arguments in favor of web scraping are provided in this article.
The objective is to gather data from the Wikipedia Home page using various web scraping methods, then parse it.
You will become more familiar with various web scraping methods, Python web scraping libraries, and data extraction and processing procedures.
Web Scraping and Python
Web scraping is essentially the process of extracting structured data from a big amount of data from a large number of websites using software that is created in a programming language and saving it locally on our devices, preferably in Excel sheets, JSON, or spreadsheets.
This aids programmers in creating logical, understandable code for both little and big projects.
Python is primarily regarded as the finest language for web scraping. It can effectively handle the majority of web crawling-related tasks and is more of an all-arounder.
How to scrape data from Wikipedia?
Data can be extracted from web pages in a variety of ways.
For instance, you may implement it yourself using computer languages like Python. But, unless you are tech-savvy, you will need to study a lot before you can do much with this process.
It is also time-consuming and might take as long as manually combing through Wikipedia pages. Moreover, free web scrapers are accessible online. Yet, they frequently lack dependability, and their suppliers may have shady intentions.
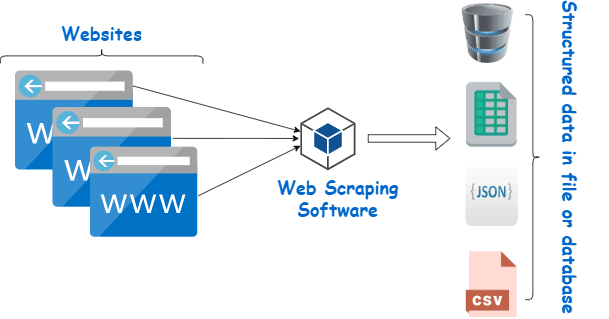
Investing in a decent web scraper from a reputable supplier is the best method to collect Wiki data.
The next step is usually simple and uncomplicated because the provider will offer you with instructions on how to install and utilise the scraper.
A proxy is a tool that you can use in conjunction with your wiki scraper to better effectively scrape data. Python-based frameworks like Scrapy, Scraping Robot, and Beautiful Soup are just a few examples of how easy it is to scrape using this language.
Proxy to Scrape data from Wikipedia
You need proxies that are extremely quick, safe to use, and guaranteed not to go down on you when you need them in order to scrape data effectively. Such proxies are available from Rayobyte at reasonable pricing.
We make an effort to offer a variety of proxies because we are aware that every user has different preferences and use cases.
Rotating proxies for web scraping Wikipedia
An instance of a proxy is one that rotates its IP address on a regular basis. Also, in order to prevent interruptions, the IP address is immediately changed when a ban occurs. This makes this particular proxy a great choice for site scraping.
Static proxies, in comparison, only have one IP address. If your ISP doesn’t enable automated replacements, you’ll run into a brick wall if you only have access to one IP address and it gets blocked. Because of this, static proxies are not the best option for web scraping.
Residential proxies for web scraping Wiki data
Residential proxies are proxy IP addresses that Internet Service Providers (ISPs) distribute and are associated with specific households. Because they come from real people, getting them is quite challenging. As a result, they are scarce and relatively expensive.

When you use residential proxies to scrape data, you appear to be an everyday user because they are linked to the addresses of real individuals.
So, using residential proxies significantly reduces your chance of being discovered and blocked. They are therefore excellent candidates for data scraping.
Rotating residential proxies for collecting wiki data
A rotating residential proxy, which combines the two types we just spoke about, is the best proxy for web scraping Wikipedia.
You can access a large number of home IPs using a proxy that rotates them frequently.
This is critical because, despite the difficulty in identifying residential proxies, the volume of requests they generate will eventually draw the attention of the website being scraped.
Rotating makes sure the project can go on even if the IP address unavoidably becomes blacklisted.
We, therefore, have what you require, whether you decide to go with several datacenter proxies or you prefer to invest in a few residential proxies.
You will enjoy the finest web scraping experience with proxies running at 1GBS speed, unlimited bandwidth, and round-the-clock customer assistance.
You may also read
- Best Web Scraping Techniques : A Practical Guide
- Octoparse Review Is It Really Good Web Scraping Tool ?
- Best Web Scraping Tools
- What Is Web Scraping ?- How It’s Used? How It Can Benefit Your Business
Why should you scrape Wikipedia?
Wikipedia is one of the most trusted and information-rich services in the online world right now. There are answers and information to almost all kinds of topics you can think of on this platform.
So, naturally, Wikipedia is a great source to scrape data from. Let us discuss the prime reasons why you should scrape Wikipedia.
Web scraping for academic research
Data collecting is one of the most painful activities involved in research. As was already discussed, web scrapers make this procedure quicker and easier while also saving you a tonne of time and energy.
With a web scraper, you may quickly scan over numerous wiki pages and collect all the data you require in an organized manner.
Assume for a moment that your goal is to determine whether depression and sunlight exposure vary by country.
You can use a Wiki scraper to locate information such as the prevalence of depression in different nations and their sunny hours instead of going through numerous Wikipedia entries.
Reputation management
Making a Wikipedia page has become a must-do marketing strategy for many different types of businesses in the modern era because Wikipedia posts frequently appear on the first page of Google.
But, having a page on Wikipedia should not be the end of your marketing efforts. Wikipedia is a crowd-sourced platform, so vandalism is something that happens rather frequently.
As a result, someone could add unfavorable information to your company’s page and harm your reputation. Alternatively, they might defame your business in a relevant wiki article.
Because of this, you must keep an eye on your Wiki page as well as other pages that mention your business once it has been made. You can do this with the aid of a wiki scraper with ease.
You can periodically search Wikipedia pages for references to your business and point out any instances of vandalism there.
Boost SEO
You may utilize Wikipedia to increase traffic to your website.
Create a list of articles you would like to change by using a Wiki data scraper to locate pages that are pertinent to your business and your target audience.
Start by reading the articles and making a few helpful adjustments to gain credibility as a contributor to the site.
Once you’ve established some credibility, you can add connections to your website at places where there are broken links or where citations are required.
Quick links
Python libraries used for web scraping
Python is the most popular and reputable programming language and web scraping tool in the world, as was already said. Now let’s look at the Python web scraping libraries that are available right now.
Requests (HTTP for Humans) Library for Web Scraping
It is used to send different HTTP requests, such as GET and POST. Among all libraries, it is the most fundamental but also the most crucial.
lxml Library for Web Scraping
Very quick and high-performance parsing of HTML and XML text from websites is offered by the lxml package. This is the one to choose if you intend to scrape huge databases.
Beautiful Soup Library for Web Scraping
Its work is building a parse tree for content parsing. A great place to start for beginners and is highly user-friendly.
Selenium Library for Web Scraping
This library solves the problem that all the libraries mentioned above have, namely scraping content from dynamically populated web pages.
It was originally designed for automated testing of web applications. Because of this, it is slower and unsuitable for tasks at the industrial level.
Scrapy for Web Scraping
A complete web scraping framework that uses asynchronous usage is the BOSS of all packages. This enhances efficiency and makes it blazingly quick.
Conclusion
So this was pretty much the most important aspect you need to know about Wikipedia Web Scraping. Stay tuned with us for more such informative posts on Web Scraping and a lot more!
Quick Links


